
HappyHorse Decoded: Why the Arena-Leading AI Video Model Appeared and Vanished
An English explainer on the sudden rise of HappyHorse 1.0, its reported architecture, benchmark lead, likely origins, and what engineering teams should do next.

Why people noticed HappyHorse so quickly
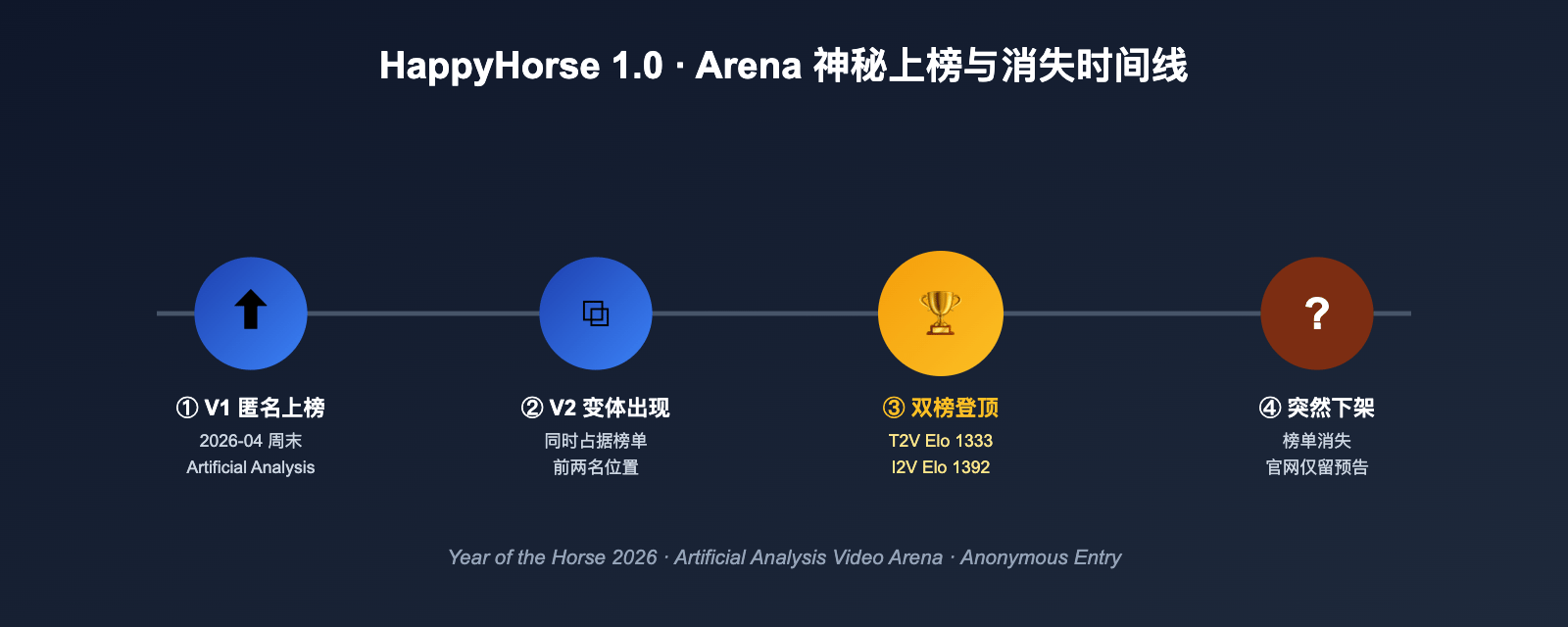
In early April 2026, a little-known video model called HappyHorse showed up on third-party blind ranking boards and immediately posted scores strong enough to overtake established names such as Seedance 2.0, Kling 3.0, and PixVerse V6 in several no-audio categories.
What made the story unusual was not only the ranking jump. HappyHorse 1.0 and a V2 variant appeared almost out of nowhere, briefly dominated the public discussion, and then disappeared from visible leaderboards just days later. That combination of strong results, vague sourcing, and fast removal triggered intense speculation across the AI video community.
What the public claims said about the model
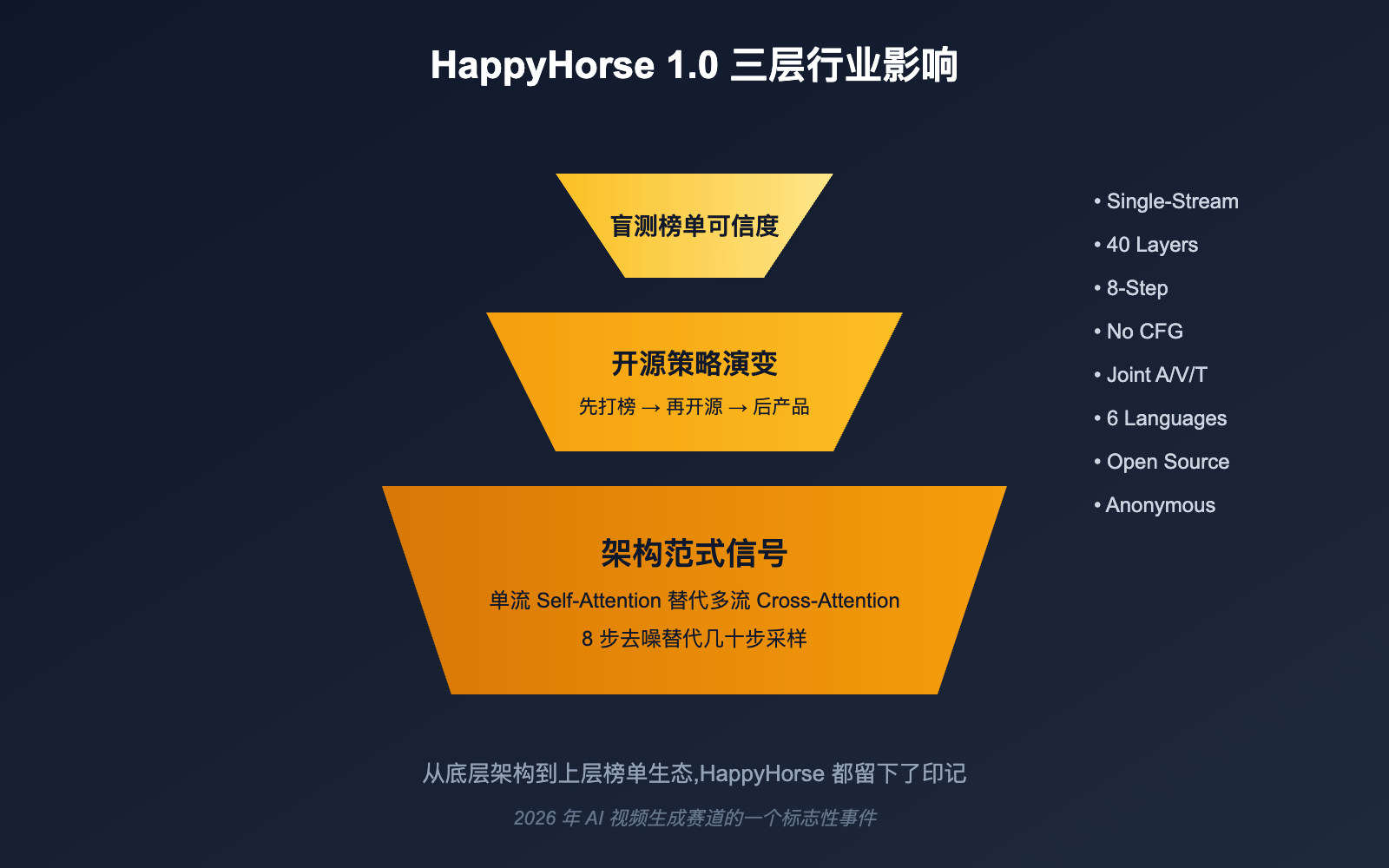
Public-facing descriptions of HappyHorse framed it as a text-to-video and image-to-video system with native audio support. The most repeated technical claim was that the model used a 40-layer single-stream self-attention Transformer instead of a more typical multi-branch architecture with separate modality paths joined through cross-attention.
Another widely repeated claim was the inference profile: eight denoising steps without classifier-free guidance. If that is accurate, it would suggest a model family optimized for shorter inference paths and better serving efficiency, potentially through distillation-heavy training.
- Reported support for text, image, video, and audio tokens in one shared sequence
- Claimed multilingual support across Chinese, English, Japanese, Korean, German, and French
- Promised release artifacts including base, distilled, and upscaling variants
Why the leaderboard results mattered
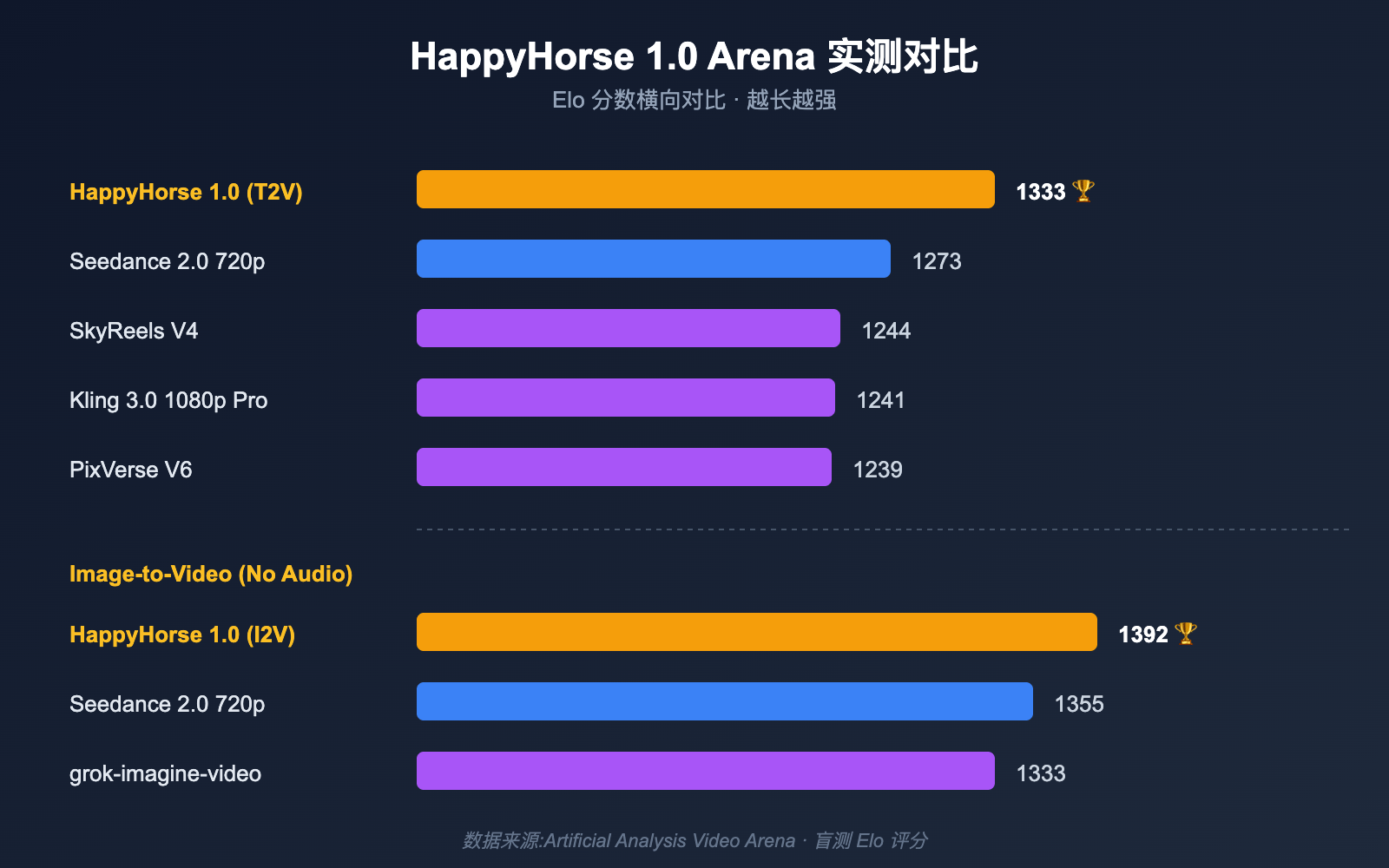
The strongest reported results came from no-audio categories. In those snapshots, HappyHorse 1.0 led both text-to-video and image-to-video tracks by meaningful Elo margins over incumbent systems. In image-to-video, the gap looked especially notable, which helps explain why people quickly linked the model to human-centric, reference-driven workflows.
Audio-enabled tracks painted a more moderate picture. HappyHorse still looked competitive, but not dominant. That nuance matters because it suggests the model may have been strongest where visual coherence and motion control mattered most, while established systems retained advantages in more complete audiovisual generation.
The architecture angle engineers cared about
If the single-stream Transformer description is directionally true, the bigger story is not brand drama but architecture direction. A unified token pipeline can reduce cross-modal plumbing, simplify optimization targets, and create a cleaner route toward synchronized audiovisual generation.
For infrastructure teams, the more practical takeaway is this: the next generation of video models may not simply be larger or slower. They may also be more deployment-friendly, with fewer inference steps and tighter serving economics than the diffusion-heavy systems many teams are used to today.
Where the model might have come from
Three explanations circulated most often. One theory tied HappyHorse to the Wan family. Another linked it to the broader Seedance ecosystem. A third, and arguably more realistic, theory was that it came from a still-unannounced Asian lab using blind rankings to establish credibility before a formal release.
None of those theories were confirmed by an official source. That is the important point. For engineering decisions, provenance speculation is less useful than the ability to test a model quickly once access becomes real.
- Wan-adjacent theory: timing and regional context matched, but technical descriptions did not fully line up
- Seedance-adjacent theory: leaderboard overlap made people suspicious, though evidence stayed weak
- Independent lab theory: the release pattern fit a credibility-first, product-later strategy
Why the disappearance was not the whole story
A model vanishing from a public board does not automatically invalidate its prior performance. The removal could reflect benchmark hygiene, anonymous testing cleanup, launch timing changes, or a shift in publication strategy.
The more durable lesson is that blind rankings are becoming part of go-to-market strategy. Teams should expect more anonymous or semi-anonymous entries to appear, spike attention, and disappear again before a full launch sequence is ready.
What product teams should do instead of guessing
The wrong response is to anchor on mystery. The right response is to treat moments like this as a workflow test. If a new model suddenly becomes available tomorrow, can your stack evaluate it without rewiring the whole product?
That means keeping prompts, evaluation sets, asset pipelines, moderation checks, and rollout logic model-agnostic wherever possible. The teams that benefit most from surprise model launches are the teams already prepared to swap providers or checkpoints quickly.
- Keep a stable internal benchmark set for your own prompts and source assets
- Compare ranking scores against business metrics such as latency, cost, and compliance
- Prefer integration layers that make model switching cheap
Bottom line
HappyHorse 1.0 mattered because it compressed several trends into one event: strong blind ranking results, a more deployment-friendly architecture story, a release strategy built around benchmark visibility, and the possibility of an eventual open release.
Whether HappyHorse becomes a lasting platform, a precursor to another public model, or simply a memorable benchmark episode, it already delivered one clear signal: AI video infrastructure is moving toward faster iteration, lower switching cost, and more aggressive competition around real-world usability.
For the practical launch story and workflow guidance behind the model, read HappyHorse Is Here at /blog/happyhorse-is-here. To see how the model ranks against Sora 2, Veo 3.1, and Kling O3 using third-party benchmarks, visit the full comparison at /blog/best-ai-video-generator-2026.
Try HappyHorse free
Create your first AI video in under 3 minutes. No credit card needed. New users get welcome credits instantly.